概要
2026年1月27日に公開されたMeta社の研究(https://arxiv.org/pdf/2601.20094v1)。
kyutai社の開発したNeural audio codec(音声を特徴量に変換して特徴量を音声に戻すことのできるネットワーク)の一種であるMimiモデルを改良しましたという話。
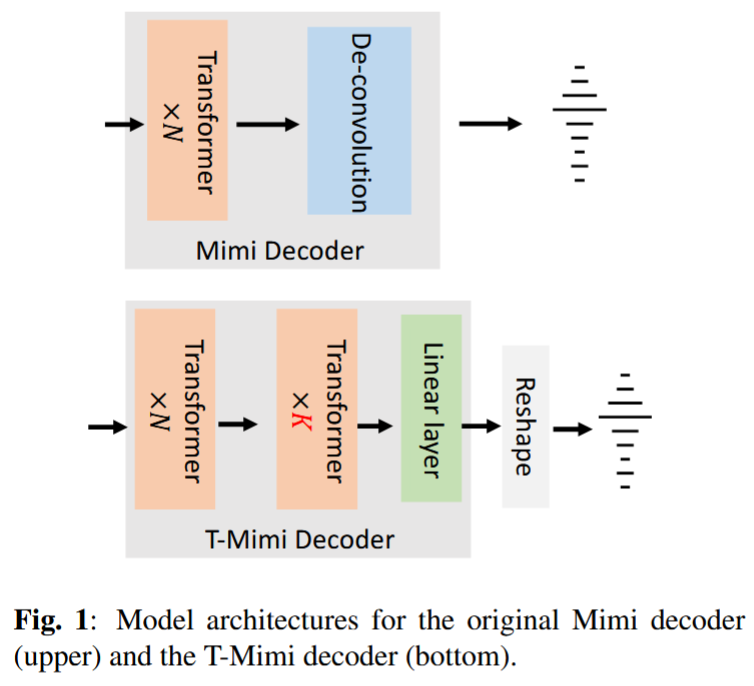
具体的には出力部分の逆畳み込み層をトランスフォーマーに置き換えて、CPUなどしかないエッジのデバイスでも高速に計算できるようにしました(42.1 ms -> 4.4 ms)!というのがメインの主張。
もう一つの主張としてはQuantization aware training (QAT)で計算機の要件を低くしたことと、音声出力に近い層(Linear layerや出力から2層分のtransfomerなど)の量子化は品質を下げるので避けた方がいいということを述べています。
量子化前後の重みの容量は163.2 MB -> 68.7 MB。
読む前の疑問
- CPU計算で早いのはわかるが、GPUでも早いのか?
- もともとDeconvolution層を入れた意図は?
Transformerに置き換えてデメリットはないのか? - 基本的にはGPU計算前提の場合はDeconvolution演算の方が早いのでは?
前提知識
知っている部分は読み飛ばしてください。
Mimiモデルとは
Mimiモデルはkyutai社が開発・公開しているNeural Audio codec。
特徴
- semantic情報(テキストで表現できる情報)とacoustic情報(感情などテキストだけでは表現できない情報)に明確に分けて特徴量を取り扱う
- 低いトークンのフレームレート(12.5 Hz)で音声情報を扱うことができる
- Streamingをサポートしていてリアルタイムに音声をエンコーディングとでコーディイングできる。
- Mimiを構成要素に持つMoshiモデルはfull duplexで有名なモデルで、会話の際にモデル側で明確にターンの分離が必要なく、自然な相槌や発言のオーバーラップができる。
Quantization aware training (QAT)
内部では32bitで重みを保持しつつも、順伝播の計算時には量子化した重みを使用して出力を計算することで、トレーニングの時から、量子化を前提に学習すること。
逆に、学習時は量子化せずに、学習終了後の推論時のみ量子化することはpost-training quantizationと呼ばれる。
Quantization aware trainingは学習中の損失は量子化を前提としているため、post-training quantizationよりも精度を保ちやすいとされている。
手法
具体的なアーキテクチャの話
Deconvolution層をTransformer層と2層のLinear層で置き換えた。
Linear層の1層目はバイアスありで、2層目はバイアスなしとのこと。
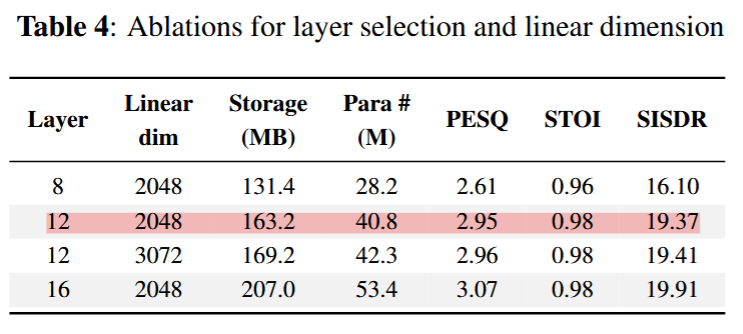
初期の実験でTransformer層はwideな8層構造よりも、12層の方がパフォーマンスがよかったらしい。考察としては12層の方はオリジナルの8層のMimiモデルの重みを初期値として使用できたことを挙げている。
wideな8層の初期値をどうしたのかは気になるところ…
トレーニング
T-Mimiのエンコーダー部分は固定。デコーダー部分のみ学習。
LossはGANのlossの複合損失と再構成損失で以下の4種類の重み付き和。(数式は論文にないので勝手につけています。)
- multi-scale mel-spectrogramの再構成損失(L1)。重みは2.0。
multi-scale mel-spectrogramの計算方法
scaleは短時間フーリエ変換(STFT)する際のサンプル数\(N_s\)、ウィンドウサイズ\(W_s\)、ホップサイズ(サンプル幅をずらすステップ数)\(H_s\)のセット\((N_s, W_s, H_S)\)です。
まず一つのスケールでのmel-spectrogramの再構成損失を計算してからそれぞれの平均を計算します。
以下では\(x_k \in R^T\)はk番目のフレームの入力の波形、\(\hat{x}_k \in R^T\)はモデルの出力波形です。
ステップ1: 周波数領域への変換
\[X_{s,k} = \mathrm{STFT}_{N_s, H_s, W_s}(x_k)\]
周波数領域に変換された\(X_s\)を損失の計算に使用します。
\[\hat{X}_{s,k} = \mathrm{STFT}_{N_s, H_s, W_s}(\hat{x}_k)\]
出力\(\hat{x}_k\)も同様に周波数領域に変換します。
ステップ2: 振幅スペクトログラムの計算(位相成分の除去)
\[A_{s,k} = |X_{s,k}|, \hat{A}_{s,k} = |\hat{X}_{s,k}|\]
複素数である\(X_{s,k}\)の絶対値を計算することで振幅成分のみを取り出します。
ステップ3: mel filter bankをかけてmel-spectrogramを作る
人の知覚はすべての周波数を同じように扱うわけではないので、一定範囲の周波数の振幅の重み付き平均をとることで、人の知覚を反映した特徴量にしたものをmel-spectrogramと呼びます。
\[S_{s,k} = M_s A_{s,k}, \hat{S}_{s,k} = M_s \hat{A}_{s,k}\]
ステップ4: Lossの計算
\[L_s^\mathrm{mel} = \frac{1}{F_s K_s} \sum_{f=1}^{F_s} \sum_{k=1}^{K_s} \|\log(S_{s,k}+\epsilon)−\log(\hat{S}_{s,k}+\epsilon)\|_1\]
\(\epsilon\)はlogの中が0になるのを防ぐための小さな数。
ステップ5: 複数のscaleのLossの和を計算
\[L^\mathrm{multi-scale mel} = \frac{1}{N_s} \sum_{s=1}^{N_s} L_s^\mathrm{mel}\]
- 最小二乗GAN損失。重みは4.0。
最小二乗GAN損失の計算方法
識別器\(D\)は入力を\(x\)、出力が本物の信号なら1、生成された信号なら0を出力するネットワークです。
生成器側で使用するlossは、識別器で1が出力されるように重みを更新したいので
\[L^\mathrm{adv}=E[(D(\hat{x})-1)^2]\]
を使用する。
識別器側で使用するlossは
\[L^D=E[(D(x)-1)^2] + E[(D(\hat{x}))^2]\]
で学習する。
識別器側はMulti-Scale STFT DiscriminatorがMimi系では使用される。
識別器には短時間フーリエ変換した結果の実部と虚部をチャンネルとして入力する。
\[X_{s,k} = \mathrm{STFT}_{N_s, H_s, W_s}(x_k)\]
Mimiでは識別器として2次元の畳み込み層を6層重ねたネットワークを使用している。
詳細はaudiocraft(https://facebookresearch.github.io/audiocraft/api_docs/audiocraft/adversarial/discriminators/msstftd.html)を参照?
- feature matching loss。重みは4.0。
feature matching lossの計算方法
feature matching lossのfeatureは識別器の特徴量を指しています。
識別器\(D\)のスケール\(s\)に対する\(l\)層目の中間特徴量を\(D^{(l)}_s (\cdot)\)とするとlossは
\[L^\mathrm{FM} = \frac{1}{N_s L_s}\sum_{s=1}^{N_s} \sum_{l=1}^{L_s} \|D^{(l)}_s (x)−D^{(l)}_s (\hat{x})\|_1\]
- 波形のL1 loss。重みは0.1。
\[L_{L1} = \|x-\hat{x}\|_1\]
トレーニングは二段階で実行される。
第一段階ではすべての複合lossを使用。
第二段階ではfeature matching lossのみで学習。
学習時の工夫として、モデルに沈黙をきれいに学習させるために学習サンプルの10%の前後に純粋な沈黙の音声を追加して学習している。
実験
学習データとオプティマイザ
500万時間のMETA独自のspeechデータセット。
オプティマイザはAdamを使用。学習率は\(5 \times 10^{-5}\)。
Quantization aware trainingは 8-bitのpre-channel quantizationを使用。
QAT中のAdamの学習率は\(1 \times 10^{-5}\)
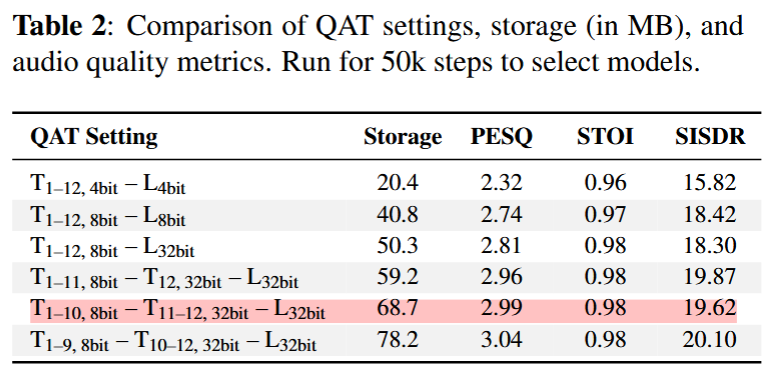
モデル量子化の中間評価
表のQAT Settingは例えば\(T_{1-12, 4\mathrm{bit}}-L_{4\mathrm{bit}}\)の場合、Transformerは12層すべてで4bit量子化、Linear層も4bitで量子化していることを表す。
Table 2は50k steps時点の評価。
Storageが小さく、PESQが大きいほどいいモデル。論文では\(T_{1-10, 8\mathrm{bit}}-T_{11-12, 32\mathrm{bit}}-L_{32\mathrm{bit}})を最後まで学習するモデルに選択している。
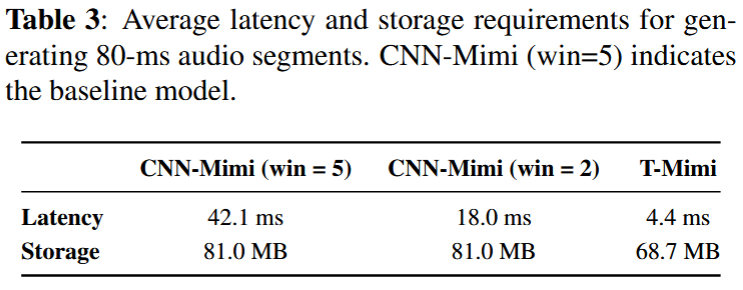
推論速度
推論の速度をTTSシステムの一部として使用して、Samsung Galaxy S22 smartphoneで計測した結果がTable 3。
Transformer層の数と性能の改善
Table 4にあるように8層から12層への変化が一番改善度が大きい。
まとめ
Mimiモデルとその発展形のT-Mimi、面白そうですね。個人開発でAI Vtuber作ってみたいのでfull duplexなモデルを探していてこの論文見つけました。
もっと知りたい方はkyutai社などを調べてみるといい情報得られると思います。

コメント