
今更ながら画像生成にチャレンジしてみました。
ツイッターで@br_dさんの画像をみて感銘を受けたのがきっかけです。
使用したツールはComfyUIで、最近も開発が続いている有力なツールです。
下記図のように生成モデルの大枠も透けて見えるようなツールなので勉強にもなるかなと思って採用しました。
いろいろ機能はあるみたいですが今回は一番シンプルな構成で遊んでみました。
モデルは自分でダウンロードしてきて使う形でbrdrXL_v04hというものを今回使いました。
モデルがいいのか、意外といいイラストが作れて楽しいです。
イラストは好きだけど絵心はない人でもいろいろ試せるのが生成AIのいいところかなと思います。
基本的には文章を生成モデルに与えて、画像が出力される仕組みになっています。
例えばサムネは以下のプロンプトで作っています。
ほかのプロンプトもメモとして残しておきます(触っているうちに忘れてしまったものもあります。)
ポジティブ
girl, hakama, 1katana at the left waist, long hair touch ground, back view, sad, white background, monochrome single heavy black brush stroke, haboku, big red moon
ネガティブ
looking away
練習
chatgpt先生にいくつかお題を出してもらってその画像の生成を目指しました。
夕方の駅のホームで、背中だけが見える人物
地味にお題とは異なるのですが以下のような画像生成できました。
服装などの指定は結構反映されるのですが、背景(駅のホームなど)をうまく出すのは結構難しい印象です。

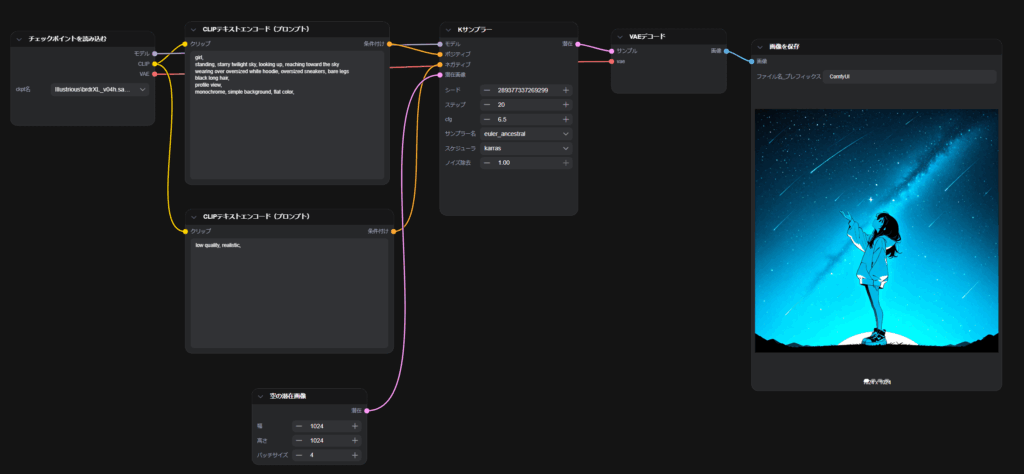
ホームを出すのが難しかったので夜にしてみました。

ポジティブ
girl, standing, starry twilight sky, looking up, reaching toward the sky wearing over oversized white hoodie, oversized sneakers, bare legs black long hair, profile view, monochrome, simple background, flat color,
ネガティブ
low quality, realistic,
インナーカラー赤
キャラの設定については結構入力に対する忠実度が高い気がします。インナーカラー指定すると結構しっかり反映されました。

インナーカラー青くしたりもできました。

今回はここまで。
次回は遊びながら何かしらオリジナルキャラでも作って同じキャラのままいろいろな画像を生成するみたいなことができないか試してみたいと思います。

コメント